1つインデックスを作成したらINSERT&UPDATEはどれぐらい遅くなる?
遅いSQLのチューニングをしており、色々分析を進めた結果、新しいインデックスを作成すれば改善する見込みがたちました。 そこで新しいインデックスを作成する準備をしていたところ、QAチームの人から
「インデックスを作成するとINSERTとUPDATEが遅くなるはず。 どれぐらい遅くなるか示してください」と言われました。」
私はインデックスを作成するとINSERTとUPDATEが遅くなるというのは知識としては知っており、
また過去の経験から「遅くなるっていっても大したことないだろ〜」という感覚ではいるのですが、数字で示すことができなかったので、これを機に検証してみました。
方針
DBはAWSのRDSを使っているので、本番DBのスナップショットから復元したDBに対して検証をおこないました。
インデックス追加前とインデックス追加後の状況それぞれで、INSERTとUPDATEの時間を計測します。INSERT,UPDATEする件数は1,000,10,000,100,000の3バリエーション実施します。 (ちなみに対象テーブルのレコード件数は約80,000,000でした)- 計測のブレを減らすために、それぞれのバリエーションについて
5回実施して平均値を比較します。
以下の表を埋めるイメージです。
| INSERT (1,000) |
UPDATE (1,000) |
NSERT (10,000) |
UPDATE (10,000) |
NSERT (100,000) |
UPDATE (100,000) |
|
|---|---|---|---|---|---|---|
| インデックス追加前 (単位は秒) |
||||||
| インデックス追加後 (単位は秒) |
やり方
対象テーブル
対象テーブルの定義は、参考として以下のような定義とします。
CREATE TABLE user( user_id INT PRIMARY KEY, username VARCHAR(50) NOT NULL, email VARCHAR(100) UNIQUE, password_hash VARCHAR(255) NOT NULL, first_name VARCHAR(50), last_name VARCHAR(50), date_of_birth DATE, created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP, last_login TIMESTAMP, is_active BOOLEAN DEFAULT TRUE );
件数増幅用テーブル
今回この件数増幅用テーブルがキモになります。 このあとのINSERT文で、クロスジョインを繰り返すことで件数を増幅させます。
CREATE TABLE numbers( `no` int DEFAULT NULL ); INSERT INTO numbers VALUES (1), (2), (3), (4), (5), (6), (7), (8), (9), (10);
INSERT文
INSERT INTO user SELECT @rownum := @rownum + 1, -- user_id 'INDEX-PERFORMANCE-TEST', -- username CONCAT('I-', LPAD(@rownum, 98,'0')), -- email CONCAT('I-', LPAD(@rownum, 253,'0')), -- password_hash CONCAT('I-', LPAD(@rownum, 48,'0')), -- first_name CONCAT('I-', LPAD(@rownum, 48,'0')), -- last_name now(), -- date_of_birth now(), -- created_at now(), -- last_login true -- is_active FROM (SELECT @rownum := 0) AS v, numbers AS s1, -- 10件 numbers AS s2, -- 100件 numbers AS s3, -- 1,000件 numbers AS s4, -- 10,000件 numbers AS s5 -- 100,000件;
UPDATE文
UPDATE user SET user_id = user_id, email = CONCAT('U-', LPAD(user_id, 98, '0')), password_hash = CONCAT('U-', LPAD(user_id, 253, '0')), first_name = CONCAT('U-', LPAD(user_id, 48, '0')), last_name = now(), date_of_birth = now(), created_at = now(), last_login = now(), is_active = true WHERE username = 'INDEX-PERFORMANCE-TEST';
レコード削除SQL
DELETE FROM user WHERE username = 'INDEX-PERFORMANCE-TEST';
結果
| INSERT (1,000) |
UPDATE (1,000) |
NSERT (10,000) |
UPDATE (10,000) |
NSERT (100,000) |
UPDATE (100,000) |
|
|---|---|---|---|---|---|---|
| インデックス追加前 (単位は秒) |
0.15 | 0.35 | 1.24 | 2.86 | 14.44 | 29.42 |
| インデックス追加後 (単位は秒) |
0.17 | 0.39 | 1.29 | 3.11 | 13.35 | 31.19 |
※ INSERT(100,000)がなぜかインデックス追加後のほうが早くなっているが誤差だと思われる...
INSERTとUPDATEについては、想定通りインデックス追加後のほうが遅くなっていますが、微々たるものです。 体感でいうと、1,000件, 10,000件ではほとんど変わらず、100,000件で少し遅いと感じる程度です。 結論としてはよ、INSERT&UPDATEが多少遅くなったとしても今回のインデックス追加はしたほうが良いと考えます。
終わりに
「遅くなるっていっても大したことないだろ〜」という感覚を、数字で示すことができました! 上記結果をQAチームに見てもらい、「なるほど!確かにこれだったらインデックス追加したほうがメリット多いですね!ぜひよろしくお願いします!」
と言ってもらえたので満足です!
最もカーディナリティの高いカラムをインデックスの一番左に置けばよいわけではない
SQLチューニングをしている中で、なぜかインデックスをうまく使ってくれないクエリがあり、色々調べたところ『最もカーディナリティの高いカラムをインデックスの一番左に置けばよいわけではない』ということがわかったので、メモとして残したいと思います。
先に結論
複合インデックスではカーディナリティが高いカラムを左側にすべき。
ただし、範囲検索されるカラムはカーディナリティが高くてもインデックスの右側にすべき!
カーディナリティとは?
カラムに格納されているデータの種類がどのくらいあるのか(カラムの値の種類の絶対値)を、カーディナリティといいます。 カーディナリティの値によって、「カーディナリティが低いカラム」「カーディナリティが高いカラム」という言い方をします。
カーディナリティが低いカラム
例えば性別というカラムがあり、中身が男か女の二種類しかないのであれば、性別カラムのカーディナリティは2です。 他にもフラグのような0か1しかないようなカラムも、カーディナリティが低いと言えます。
カーディナリティが高いカラム
IDや日付のようなカラムであれば、たくさんのバリエーションの値が存在しています。 こういったカラムをカーディナリティが高いと言います。
カーディナリティとインデックス
インデックスはカーディナリティが高いカラムに対して作成すべき。
範囲検索されるカラムを含む複合インデックスについて
以下のようなuserテーブルを題材に説明します。
| id | name | class | birthday |
|---|---|---|---|
| 1 | 佐藤 | A | 04/29 |
| 2 | 鈴木 | B | 06/27 |
| 3 | 高橋 | B | 04/11 |
| 4 | 田中 | A | 08/12 |
| 5 | 伊藤 | B | 10/15 |
| 6 | 渡辺 | C | 10/28 |
| 7 | 山本 | A | 03/31 |
| 8 | 中村 | B | 02/11 |
| 9 | 小林 | C | 01/24 |
| 10 | 加藤 | A | 05/08 |
| 11 | 吉田 | B | 05/30 |
| 12 | 山田 | C | 07/11 |
| 13 | 佐々木 | A | 05/03 |
| 14 | 山口 | B | 12/19 |
| 15 | 松本 | C | 04/26 |
| 16 | 井上 | A | 01/08 |
| 17 | 木村 | B | 11/26 |
| 18 | 林 | C | 11/16 |
範囲検索するにしても検索条件が1つであれば簡単です。 birthday カラムのインデックスを作成すればよいだけです。
-- 1月から6月生まれの人を抽出する SELECT name FROM user WHERE birthday '01/01' AND '06/30'
では検索条件が複数ある場合はどうでしょうか?
-- Bクラスで1月から6月生まれの人を抽出する SELECT name FROM user WHERE class = 'B' AND birthday BETWEEN '01/01' AND '06/30'
classはA,B,Cしかないため、カーディナリティは3です。一方birthdatyのカーディナリティは日付なので多いはずです。今回だと全員日付が違うので18です。 「インデックスはカーディナリティが高いカラムに対して作成すべき」というセオリーの通りであれば、 birthday->class 順の複合インデックスを作ることになります。 以下の図は、birthday->classの複合インデックスの場合の、Bクラスで1月から6月生まれの人を抽出するSQLを実行した際のインデックス走査の様子です。
なおインデックスの走査方法については以下の記事をご参照ください。 tomozo6.hatenablog.jp

図の通り、日付が最初に一致するエントリから、 最後に一致するエントリまでがスキャンの範囲になります。今回だと実に4つのリーフノードを走査する必要があります。 ❌印のエントリは、class=Bではないので抽出しません。つまり無駄に走査していることになり非効率です。
一方以下の図は、セオリーとは違う class -> birthday の複合インデックスの場合です。

class=Bとインデックスの最初のカラムが1つの値に定まっています。 classがBの範囲内でbirthdayのカラムが順番に並んでいるので、無駄な走査がありません。 リーフノードも2つの走査で済みます。
日付の範囲が広がれば広がるほど、パフォーマンスの違いは大きくなっていきます。
まとめ
複合インデックスではカーディナリティが高いカラムを左側にすべき。ただし、範囲検索されるカラムは、カーディナリティが高くてもインデックスの右側にすべき!
赤文字部分が今回判明した新しいセオリーです。 等号(=)で1つの値に定められるカラムは、範囲検索される前に先にインデックスで走査させる。とも言い換えれます。
インデックスがあるはずなのに、 範囲検索しているSQLが遅い! ということがあれば、これが原因の可能性がありますので、皆さんも是非一度自身の環境のインデックスを見てみてください!
MySQLのB+treeインデックスの復習
最近あるプロダクトの性能改善をおこなっており、その中で特にMySQLのチューニングを担当しています。 RDBのチューニングといえばまずはインデックスです。「インデックスを作成すれば早くなる!」というのは感覚的にはわかっているのですが、インデックスがどんな仕組みになっているのか? について少しだけ踏み込んで理解したいと思ったため、勉強してみました。
お題
例えば以下のようなuserテーブルで、『誕生日が 10/15 の人はだれですか?』を検索する場合を考えてみます。
| id | name | class | birthday |
|---|---|---|---|
| 1 | 佐藤 | A | 04/29 |
| 2 | 鈴木 | B | 06/27 |
| 3 | 高橋 | B | 04/11 |
| 4 | 田中 | A | 08/12 |
| 5 | 伊藤 | B | 10/15 |
| 6 | 渡辺 | C | 10/28 |
| 7 | 山本 | A | 03/31 |
| 8 | 中村 | B | 02/11 |
| 9 | 小林 | C | 01/24 |
| 10 | 加藤 | A | 05/08 |
| 11 | 吉田 | B | 05/30 |
| 12 | 山田 | C | 07/11 |
| 13 | 佐々木 | A | 05/03 |
| 14 | 山口 | B | 12/19 |
| 15 | 松本 | C | 04/26 |
| 16 | 井上 | A | 01/08 |
| 17 | 木村 | B | 11/26 |
| 18 | 林 | C | 11/16 |
検索SQL
SELECT name FROM user WHERE birthday = '12/19'
作成するインデックス
この検索が早くなるようするためには、birthday列に対してインデックスを作成することになります。
CREATE INDEX idx_user_birthday ON user(birthday)
インデックスをB+treeで表現
B+treeインデックス自体の説明は他にいくらでも記事があると思うので省略します。

上の図は、今回の例をB+treeインデックスで表現したものです。各ノードの中身は、それぞれ1つ下のノードの最大値となります。

上の図は、左側のブランチノードとリーフノードを抜粋したものです。
例えば一番左のリーフノードの最大値は02/11なので、ブランチノードの最初の要素も02/11になります。
ここではブランチノードとリーフノードのみを例に挙げていますが、ルートノードだとうと同じ仕組みです。
インデックスの走査の仕組み
インデックスの走査は、一番上のルートノードから始まります。そしてノード内の左の要素から順番に、検索する値以上であるかをチェックします。要素が検索する値以上であれば、その要素に対応するブランチノードへのポイントを辿ります。これをリーフノードに達するまで繰り返します。

上の図は、『誕生日が10/15の人』を検索した際に、インデックスをどのように辿るかを表現したものです。 インデックスを以下のような順番で辿ることになります。
10/15 =< 05/06は偽なので次の要素に10/15 =< 12/19は真なので 12/19に対応するブランチノードに移動10/15 =< 12/19は偽なので次の要素に10/15 =< 10/28は真なので 10/28に対応するブランチノードに移動10/15 =< 08/12は偽なので次の要素に10/15を発見!
これぐらいのデータ量だとありがたみがわかりづらいですが、B+ツリーの走査は非常に効率的な処理です。巨大なデータセットに対してもほとんど一瞬で処理できます。
MySQLの.mylogin.cnfを使ってみる
今まではMySQLの接続情報を .my.cnf に保存して楽をしていましたが、 .mylogin.cnf という形式があるというのを恥ずかしながら最近知りました。
.my.cnf と .mylogin.cnf は、どちらも MySQL サーバーへの接続に使用される設定ファイルです。認証情報を保存することができ、設定するとログインパスを指定するだけでMySQLにログインできるようになります。
.my.cnf はクレデンシャル情報(ユーザー名やパスワード)が平文で保存されるため、セキュリティ上の懸念があるのに対し、 .mylogin.cnf はクレデンシャル情報を暗号化することが可能なので、.my.cnf に比べてセキュリティが高いです。
なお .mylogin.cnf はmysql_config_editorユーティリティを使用して作成します。
使い方
ログインパスの設定をする必要があります。
ログインパスとは
.mylogin.cnf の各オプションのグループを「ログインパス」と呼びます。 ログインパスは、接続先のMySQLサーバーおよび認証に使用するアカウントを指定する一連のオプショングループと考えてください。 暗号化を解除した例を次に示します。
[client] user = mydefaultname password = mydefaultpass host = 127.0.0.1 [tomozo6] user = tomozo6user password = tomozo6pass host = localhost
なおcat等で.mylogin.cnf
ログインパスの設定
mysql_config_editorユーティリティを使用してログインパスを設定します。 構文は以下の通りです。
$ mysql_config_editor set --host=${接続するサーバ} --login-path=${ログインパス名} --user=${使用するMySQLのユーザー} --password
なお使用するログインパスを明示的に示す --login-path=オプションを指定しない場合、mysql_config_editor はデフォルトでclientログインパスを操作します。
今回はローカルのMySQLにmysqlユーザーで接続できるように設定します。
$ mysql_config_editor set --host=localhost --login-path=tomozo6 --user=tomozo6user --password Enter password: ※パスワードを入力する
設定内容と確認
mysql_config_editorのprintコマンドを使うことで設定内容を確認できます。
$ mysql_config_editor print --all [tomozo6] user = "tomozo6user" password = ***** host = "localhost"
MySQLに接続
mysqlコマンドを使えば .mylogin.cnf の設定が読み込まれます。ただ何も指定しないと、clientログインパスを参照するので、client以外のログインパスを使用したい場合は明示的に指定する必要があります。
$ mysql --login-path=tomozo6 Welcome to the MySQL monitor. Commands end with ; or \g. Your MySQL connection id is 20 Server version: 8.0.29 MySQL Community Server - GPL Copyright (c) 2000, 2022, Oracle and/or its affiliates. Oracle is a registered trademark of Oracle Corporation and/or its affiliates. Other names may be trademarks of their respective owners. Type 'help;' or '\h' for help. Type '\c' to clear the current input statement. mysql>
設定したログインパスを削除
設定したログインパスを削除するにはremoveコマンドを使用します。
$ mysql_config_editor remove --login-path=tomozo6 $ mysql_config_editor print --all $
以下のように--userなどの指定した部分だけを削除することもできます。あんまり使うシチュエーションは思いつきませんが...
$ mysql_config_editor remove --login-path=tomozo6 --user $ mysql_config_editor print --all [tomozo6] password = ***** host = "localhost"
Q&A
Q: 暗号化ってどうやっている?鍵は? A: 実は複号に使う鍵と暗号化されたデータが .mylogin.cnf 内に一緒に格納されています。なので暗号化と言いつつ、 .mylogin.cnf ファイル単体で解読できてしまう。暗号化よりも難読化のほうが正しい表現かもしれません。
参考文献
MySQL 8.0 リファレンスマニュアル::4.6.7 mysql_config_editor — MySQL 構成ユーティリティー
AWS RDS(Aurora MySQL)のスロークエリログをpt-query-digestで解析する
✨目的や背景
MySQLのパフォーマンスチューニングをする際に、pt-query-digestでスロークエリログ(以下、スローログとする。)を分析をするのはわりと一般的だと思います。
pt-query-digestを使用するには生のスローログファイルが必要ですが、AWS RDSのスローログは、CloudWatch Logsに出力されます。 ※スローログの出力先として、CloudWatch Logsの他にMySQLのテーブルに書き込む方法もありますが、あまり使っている人はいないと思うので割愛します。
そのため、CloudWatch Logsのスローログを、生のスローログファイルとしてローカルに持ってきたいです。いろいろ試したのですが、一番楽にできた方法をメモしておきます。
🏗アーキテクチャ
スローログファイルの準備
CloudWatch Logs Insightを使用します!

スローログを出力している「ロググループ」と「分析したい期間」を指定して以下の単純なクエリを実行します。
fields @message | sort @timestamp desc | limit 1000
※リミットは念のためつけてます。無くてもよいです。
クエリ結果をJSON形式でエクスポートして、自分のPCにダウンロードします。

あとはローカルで、jqコマンドを使って生ログの形式に整形します。
cat logs-insights-results.json | jq -r '.[]."@message"' -r > slow.log
pt-query-digestで解析
これでスローログの生ログファイルができたので、あとは普通にpt-query-digestで解析するだけです。
# 普通に解析する場合 pt-query-digest slow.log # 合計実行時間でソート(私がよく使うオプションです) pt-query-digest --order-by Query_time:sum slow.log
🤔 検討した別の方法(またなぜその方法にしなかったのか?)
AWS CLI方式
AWS CLIのaws logs get-log-eventsを使っても、スローログをローカルに持ってくることができます。ただこのコマンドには「応答サイズ1MBに収まる最大ログイベント数で、最大10,000ログイベント」という上限があり、今回対象のRDSのスローログは、結構な量があったためこの上限に引っかかってしまいました。
応答に含まれるトークンを使用すれば残りのログを取得できるのですが、ちょっと面倒になったのでAWS CLI方式は見送りました。
またaws logs get-log-eventsはログストリーム1つしか指定できないので、ログストリームが複数ある場合は意識する必要がありそれもデメリットです。
📝 まとめ
最初はAWS CLI方式でスクリプトを作ろうと思っていたのですが、単発実行であればCloudWatch Logs Insightを使ったほうが楽だな〜と思いました。 頻繁にやる作業ではないのですが、必要になるときはそれなりにあると思うので、参考にしていただければと思います。
ECS&RDSの起動と停止をLambda無しで自動化してみた
✨目的や背景
AWSのコスト削減のために、本番環境以外のECSとRDSについて、平日夜間と休日は自動で停止するようにしたい。というありふれた目的です。 実はその仕組みはLambdaで構築済みなのですが、最近はLambdaでコードを書かなくても実現ができそうだったので試してみました。
🏗アーキテクチャ
EventBridgeスケジューラを使用して、ECSとRDSを直接停止・起動をさせます。めちゃくちゃシンプルです。 シンプルすぎて図を載せるのもはばかられるのですが一応載せます...。

試したところ結構良さそうだったので、今までのLambda方式から移行しちゃいました。
具体的なTerraformコード
IAM Role
ECS ServiceとRDS用の権限を付与しています。
resource "aws_iam_role" "turn_off_on" { name = "turn-off-on-role" assume_role_policy = jsonencode({ Version = "2012-10-17" Statement = [ { Action = "sts:AssumeRole" Effect = "Allow" Sid = "" Principal = { Service = "scheduler.amazonaws.com" } }, ] }) } resource "aws_iam_policy" "turn_off_on" { name = "turn-off-on-policy" policy = jsonencode({ Version = "2012-10-17" Statement = [ { Action = [ "ecs:UpdateService", "rds:StartDBCluster", "rds:StopDBCluster", ] Effect = "Allow" Resource = "*" }, ] }) } resource "aws_iam_role_policy_attachment" "turn_off_on" { role = aws_iam_role.turn_off_on.name policy_arn = aws_iam_policy.turn_off_on.arn }
Scheduler
停止用と起動用としてそれぞれスケジュールを作成する必要があります。具体的には以下のような内容のスケジュールを作ってみます。
| 種別 | 対象 | 内容 |
|---|---|---|
| 停止 | ECS Service | 平日22:00に0台にする |
| 起動 | ECS Service | 平日09:00に2台にする |
ECS Cluster名とECS Service名を指定する必要がありますが、ここではvariableにしておきます。
variable "ecs_cluster_name" { type = string } variable "ecs_service_name" { type = string }
EventBridgeスケジューラは、タイムゾーンを指定できて直感的にcron式を書けるから好きです。
# ----------------------------------------------------------------------------- # Turn off the ECS service # ----------------------------------------------------------------------------- resource "aws_scheduler_schedule" "turn_off_ecs" { name = "turn-off-ecs-schedule" schedule_expression_timezone = "Asia/Tokyo" schedule_expression = "cron(0 22 ? * MON-FRI *)" target { arn = "arn:aws:scheduler:::aws-sdk:ecs:updateService" role_arn = aws_iam_role.turn_off_on.arn input = jsonencode({ Cluster = var.ecs_cluster_name Service = var.ecs_service_name DesiredCount = 0 }) } flexible_time_window { mode = "OFF" } } # ----------------------------------------------------------------------------- # Turn on the ECS service # ----------------------------------------------------------------------------- resource "aws_scheduler_schedule" "turn_on_ecs" { name = "turn-on-ecs-schedule" schedule_expression_timezone = "Asia/Tokyo" schedule_expression = "cron(0 9 ? * MON-FRI *)" target { arn = "arn:aws:scheduler:::aws-sdk:ecs:updateService" role_arn = aws_iam_role.turn_off_on.arn input = jsonencode({ Cluster = var.ecs_cluster_name Service = var.ecs_service_name DesiredCount = 2 }) } flexible_time_window { mode = "OFF" } }
🤔 検討した別の方法(またなぜその方法にしなかったのか?)
ECSのスケジュールベースでのオートスケーリング機能
概要
Application Auto Scalingをaws cliを使って設定することで、ECSのサービスもスケジュールベースでオートスケーリングさせることができます。オートスケールで0台設定することにより自動停止・起動を実現します。
Why not?
一部のECSではこの仕組みを使っていましたが、スケジュールベースの設定はマネコンから設定変更はおろか確認することすらできません。
この仕組みが後々忘れ去れた際、「どうやって自動停止・起動しているのだろう?」となったりして調査をすることになると思うのですが、マネコンから確認ができないとこの仕組みに辿り着くのが難しいと思われるため、採用しませんでした。
というか今回実際「どうやって自動停止・起動しているのだろう?」となって実際に調査に時間がかかりました...
またこの仕組みはECSでは使用できますがRDSでは使用できません。同じ目的の場合は同じ仕組みで実現したいため、採用しませんでした。
EventBridgeスケジューラ + Lambda
概要
ECSやRDSを停止・起動させるLambdaを作成し、EventBridgeスケジューラが決まった時間にそのLambdaをトリガーすることで自動停止・起動を実現します。
なおLambdaをトリガーできればよいので、EventBridgeの代わりにCloudWatch Eventsでも可能です。

Why not?
EventBridgeスケジューラだけで実現する方法と比較して、Lambdaでコードを書く必要があり、またそのコードを保守する必要があるため採用しませんでした。(使っている言語のEOL対応など)
ただしこの方法には対象のECS ServiceやRDSが増えたとしても、EventBridgeスケジューラやLambda自体を増やす必要が無いというメリットがあります。(Lambda内でfor文でまわせば)
逆にEventBridgeスケジューラだけで実現する方法だと、ECS ServiceやRDSが増えるごとに、EventBridgeスケジューラを作る必要があります。
そのためマイクロサービス化していてECS Serviceがいっぱいある場合などだと、Lambdaを使ったほうが逆にシンプルかもしれません。
📝 まとめ
いかがでしたでしょうか?私はEventBridgeスケジューラ単体で、このようなことができるとは今まで知りませんでした。調べれば、既存のLambdaをもっと置き換えできるかもしれないな〜と思いました。
GitHub Actionsで別のプライベートリポジトリを参照したい
私が所属している会社ではソース管理にGitHub Organizationを使っており、会社のルールでリポジトリの可視性設定は必ずプライベートにしなければなりません。
自分のチームではよくTerraformを触るのですが、GitHub Actionsでterraform initする際に、別のリポジトリにあるTerraformモジュールを参照したい場合があります。
こういった場合、リポジトリを跨いでいるためsecrets.GITHUB_TOKENでは対応できません。
今までであればPersonal Access Token(以下PATとする。)を発行することが多かったのですが、PATには以下のようなデメリットがあります。
- セキュリティの都合上、有効期限を設定することがベターとされており、無期限で作成したくない。
- 個人で管理するリポジトリであればあまり問題になりませんが、Organization等で複数人が管理する場合、個人のPATを使うことはそもそも避けたい。(退職時どうするか?など)
そこでGitHub Appsを用いれば、個人のPATに依存せず、また短期限のトークンを随時発行するかたちで secrets.GITHUB_TOKENの権限を超えてGitHub を操作することが可能になります。
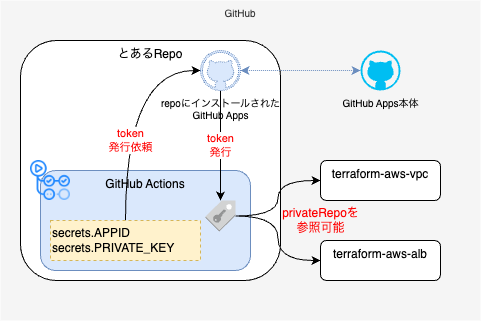
GitHub Appsの作り方
1. GitHub Appsを作成するページにアクセス
個人の場合:https://github.com/settings/apps/new
組織の場合:https://github.com/organizations/${ORG_NAME}/settings/apps/new
2. 作成するアプリの設定をする
"Register new GitHub App" セクション
Homepage URL: アプリのURL
何でも良いので適当にいれてください。
"Webhook" セクション
- **Active のチェックを外します。
"Permissions" セクション
トークンに付与する権限です。 今回はプライベートリポジトリを参照する用途なので以下の権限を付与します。
- Contents > Read-only
- Metadata > Read-only
"Subscribe to events" セクション
- Where can this GitHub App be installed: アプリをインストールできるアカウント。
「Only on this account」を設定すると、自分のみを対象にできます。
3. アプリ作成とAppID,秘密鍵情報の取得
[Create GitHub App]をクリックするとアプリが作成されます。
"About" セクションのApp IDをメモしておきます。
また "Private keys" セクションで[Generate a private key]をクリックし、 秘密鍵ファイルをダウンロードします。
GitHub App をインストールする
GitHub Appを利用するリポジトリに、作成したGitHub Appをインストールします。
- インストールするGitHub Appの左メニューから[Install App]をクリックします。
もしくは https://github.com/settings/apps/<APP_SLUG>/installations にアクセスします。 - [Install App]をクリックします。
- インストールするリポジトリを選択します。 ユーザー(or組織)の全リポジトリ、または特定のリポジトリを選択できます。
- All repositories
- Only select repositories
全リポジトリでも問題無い気はするのですが、一応セキュリティに考慮して必要なリポジトリのみを選択します。
『GitHub Actionsを実行するリポジトリ』にインストールするのはもちろんですが、『参照(クローン)されるプライベートリポジトリ』にもインストールする必要があるの注意してください。
リポジトリにGitHub App IDと秘密鍵を登録する
GitHub Actionsを実行するリポジトリのシークレットに、GitHub App IDと秘密鍵を登録します。 なお、『参照(クローン)されるプライベートリポジトリ』には登録する必要ありません。
- リポジトリの[Settings]をクリックします。
- "Secrets and variables" の[Actions]をクリックします。
- [New Repository secret]をクリックし、以下の2つのシークレットを登録します
なおリポジトリ数が多い場合はGitHubのOrganization secretsを使ったほうが楽かもです。
GitHub ActionsでGitHub Appトークンを生成する
GitHubの公式Actionactions/create-github-app-tokenを使ってトークンを作成します。
GiHub Actionsで以下のステップを入れておけば、 後続処理で他のプライベートリポジトリをクローンすることできるようになります。(Terraform のモジュール参照は裏でGit クローンしているのでこれでOK)
# 認証情報の取得 - name: Generate Github token id: generate_token uses: actions/create-github-app-token@v1 with: app-id: ${{ secrets.APP_ID }} private-key: ${{ secrets.APP_PRIVATE_KEY }} owner: ${{ github.repository_owner }} # GitHubのアクセス時に認証情報を使用するように設定 - name: Set token run: git config --global url."https://x-access-token:$GITHUB_TOKEN@github.com/OrgName/".insteadOf "https://github.com/OrgName/" env: GITHUB_TOKEN: ${{ steps.generate_token.outputs.token }}
おまけ1: tibdex/github-app-token からの乗り換え
実は公式がactions/create-github-app-tokenを出したのはわりと最近で、v1.0.0がリリースされたのが2023年6月9日でした。この公式Actionが出るまでは、個人が作成した Actiontibdex/github-app-tokenを使用するのがわりと一般的でした。私と同じようにtibdex/github-app-tokenを使用している人も多いと思うので、乗り換えする際にどういったことをすればよいのかを紹介したいと思います。
結論
GitHub Actions を以下のように変えるとうまくきます。
- name: Generate token
id: generate_token
- uses: tibdex/github-app-token@v1
+ uses: actions/create-github-app-token@v1
with:
- app_id: ${{ secrets.APP_ID }}
- private_key: ${{ secrets.APP_PRIVATE_KEY }}
+ app-id: ${{ secrets.APP_ID }}
+ private-key: ${{ secrets.APP_PRIVATE_KEY }}
+ owner: ${{ github.repository_owner }}
# GitHubのアクセス時に認証情報を使用するように設定
- name: Set token
run: git config --global url."https://x-access-token:$GITHUB_TOKEN@github.com/OrgName/".insteadOf "https://github.com/OrgName/"
env:
GITHUB_TOKEN: ${{ steps.generate_token.outputs.token }}
ポイント1: owner オプション
tibdex/github-app-tokenは、GitHub Apps がアクセスできるすべてのリポジトリに対してアクセスすることができました。
actions/create-github-app-tokenはデフォルトだと、ワークフローが動いているリポジトリのみにアクセスできるトークンが発行されます。そのため、他のリポジトリにアクセスしたい場合はownerを指定する必要があります。またrepositoriesオプションを使えば、にアクセスするリポジトリを絞ることも可能です。
上記の例では、リポジトリは絞らずownerオプションのみ追加しています。
ポイント2: 引数名
tibdex/github-app-tokeは入力パラメータである AppID と PrivateKey をそれぞれapp_idとprivate_keyという変数名で指定します。変数名そのままでもactions/create-github-app-tokenで動くは動くのですが、以下のような Warning がでます。
Warning: Input 'app_id' has been deprecated with message: 'app_id' is deprecated and will be removed in a future version. Use 'app-id' instead. Warning: Input 'private_key' has been deprecated with message: 'private_key' is deprecated and will be removed in a future version. Use 'private-key' instead.
actions/create-github-app-tokenだと、入力パラメータである AppID と PrivateKey の変数名はapp-idとprivate-keyとのこと。よって変数名を変えています。
おまけ2: 現状GitHub AppでGitHub PackageをReadすることはできない
GitHub PackageをReadするためには、従来通りPATを使うしか方法がなさそうです。 これは本当にイケてない...。